
Techbio is realizing the dream of Big Data
The new computational biology

“Cerebellar Folia” by Greg A. Dunn, whose work I first saw at the Mellon Institute at Carnegie Mellon University.
Remember the early 2010s, when people were interested in a thing called “Big Data”? The promise of Big Data was that by scaling up data collection and attacking the resulting large datasets with statistics and ML, we could uncover the hidden patterns in the vast, complex mess.
While it was criticized as faddish and buzzword-y, the interest in Big Data was definitely grounded in some real and very impactful technological developments (e.g. using social media data to improve advertising, innovated by people like Clara Shih). Peak buzzword fever died off as Big Data became the norm and data science became an established field.
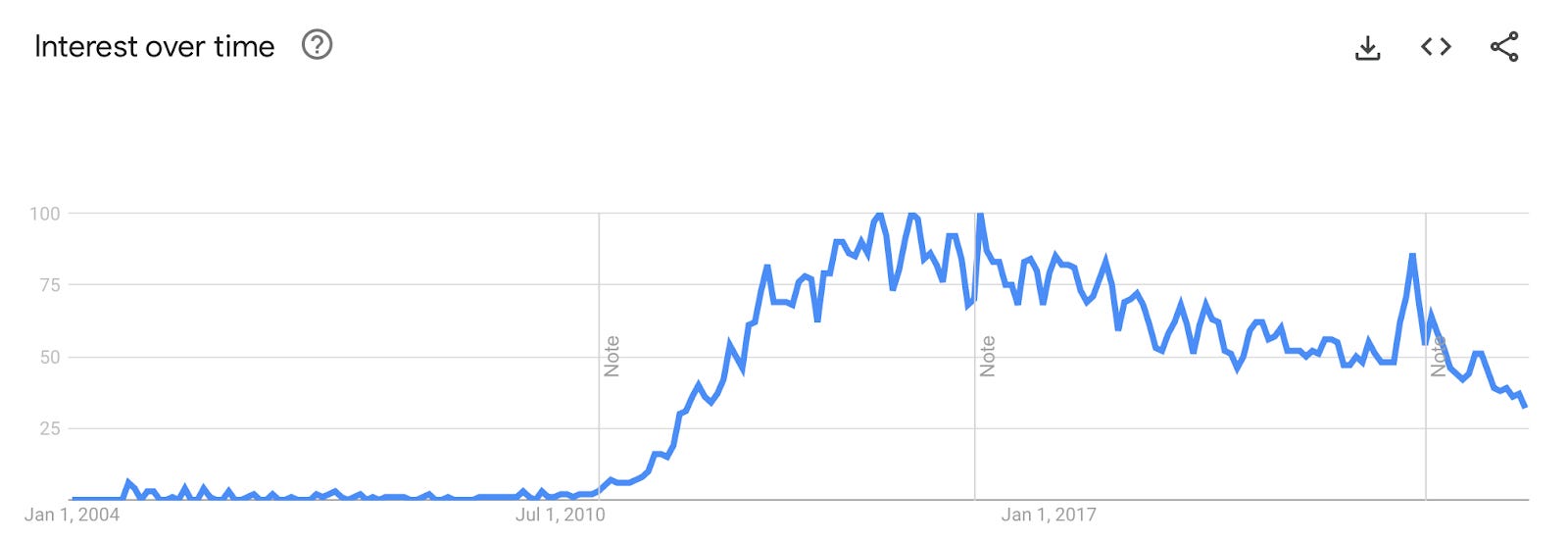
The emergence of data scientist jobs is inextricable from the use of/hype about Big Data. In 2012, HBR deemed data science the “sexiest job of the 21st century” but today, GPT-4 (and others…) seems to be coming for data scientist necks everywhere. Even without the now-ubiquitous AI panic, data science as a field seems to have fallen short of expectations. It was clear that a lot of organizations weren’t really using data scientists’ work (I’ve seen this firsthand and it’s upsetting!), and that people perceived data scientists to be worse coders.
These trends are interesting to me as a computational biologist because the rise of bioinformatics/comp bio is also heavily staked to data science. Already, bioinfo expertise seems “necessary but not sufficient,” which is a little scary considering the amount of (computational and biological) expertise that good bioinformatics work requires. Will the (imminent) fall of the data scientist mean the fall of the computational biologist?
I argue no. What’s promising to me is the rise of the techbio company: companies where tech is central to their product but biology is equally emphasized. With technologies that exponentially improve upon those of the last decade, techbio companies can finally fulfill the promise of Big Data: finding the hidden patterns in the vast, complex mess.
Why do these companies succeed where traditional data science failed? I think it’s because biologists are innovating alongside computationalists, leading to virtuous cycles of bio methods development leading to software development. A decade+ of amazing biological advances and technology development let us generate huge and informative datasets to learn on in the first place. Biologists (both experimental and computational) are creating new assays and the software to analyze the output data. As a result, computationalists and people developing DL models aren’t replacing biologists but actually working in tandem!
You can really see the benefit of this working in “amphibious” labs (and techbio companies with their own wet labs) — both labs I’ve done research in have been amphibious and I think it’s a huge strength. These labs get to develop new biological technologies and do bespoke experiments, which allows the computationalists to get more interesting results, and so on. It’s a virtuous cycle.
(As a side note, this also makes it harder for non-domain-specific AI models to eat biologists because there’s an irreproducible element of human ingenuity and spark to this biological innovation, aided by years of training. While LLMs can “read” every paper ever, biologists can tell you which papers are BS, and more importantly create new technologies and ideas undergirded by that intuition.)
To me, some very exciting examples of techbio innovation right now are protein language models and deep learning for single-cell data analysis. PLMs are so cool because they generalize really well, being able to accurately predict attributes of classes of proteins that only make up a fraction of the training data. And DL for single-cell data analysis, like cell state detection, will become even more important as the utility of stem cells for disease modeling, drug screening, and therapeutics increases. One recent paper that got me really excited unveiled scGPT, a generative model that can be used for tasks like “cell-type annotation, genetic perturbation prediction” and more.
Notice that these innovations display the domain specificity I discussed — it’s not just computational advances that drive these developments. Protein language models are enriched by biological priors (though, admittedly, Bepler and Berger mention that “Eventually, such language models may become powerful enough that we can predict function directly without the need for solved structures”).
In the case of DL for single-cell data, biologists are unequivocally in the loop. These models rely on high-quality, high-throughput experimentation, and a lot of the companies doing it have in-house wet labs to produce iPSCs and other engineered cell populations. Wet-lab and dry-lab colleagues work closely together.
And on a more general note, I’m seeing more and more biologists founding and building techbio companies, emphasizing biology and tech equally. This is a contrast to the traditional paradigm of biology as merely an application for interesting CS. Yet these new companies also emphasize the tech way more than a traditional pharma/biotech company.
One of my mentors would always say that to be a great computational biologist, it’s not enough to be a great computationalist or a great biologist. You have to be both, and you have to know the intersection well too. I think we’re now seeing his advice being borne out in the new class of companies that are taking comp bio to the next level.
If you have any thoughts/disagreements or are seeing any trends you’re particularly excited/worried about, I’d love to hear from you via email (amu.garimella@gmail.com) or comment!